Enterprise AI Has a 95% Failure Rate. Three Decisions Explain Why?

Key Takeaways
- A successful demo is not evidence of production readiness. It’s evidence of performance under ideal conditions.
- Architecture, data ownership, and reliability are the three decisions that determine whether an AI pilots ships; all three get made before model selection even happens.
- LLM-only systems carry compliance risk in regulated sectors. RAG-based grounding is the minimum bar for auditable output.
- Data is an ongoing product with a named owner, not a one-time cleanup task. Silent degradation is the cost of getting this wrong.
- Persistent memory, day-one monitoring, and separation of reasoning from execution are non-negotiable reliability infrastructure.
- Repeatability, not demo quality, is the metric that separates the 5% that ship from the 95% that don’t.
If you’ve sat through an enterprise AI demo in the last 12 months, you have probably watched the same thing happen. The model answers three questions well. The room nods. Procurement starts drafting. Then, six weeks later, quietly, the project gets shelved, not because it was bad, but because it couldn’t hold up once real users arrived.
This isn’t an unusual story. MIT’s 2025 research, widely covered by Fortune, put a number on it: roughly 95% of enterprise generative AI pilots never make it to production. In our experience working with teams across the SaaS, healthcare, and Education industries, the demo itself is usually part of the problem.
Pilots get built for pilot conditions. Clean inputs, short sessions, human oversight on every call, and a curated set of prompts the system was tuned to answer. The model looks capable because the setting has been designed, sometimes deliberately, often just by default, to make it look capable.
Production works the other way around. Inputs are messy. Contexts run long. Nobody’s supervising. Users behave nothing like QA testers, and errors cost money, create exposure, or chip away at trust before anyone notices what’s happening.
The trap here is confusion between possibility and repeatability. A demo shows that a concept can work once. Production demands it work thousands of times, unsupervised, on inputs nobody anticipated. That’s a materially different engineering problem, and most enterprises never budget for it because the demo suggested the hard part was already done.
Which is how you end up in what we’ve started calling pilot paralysis: cycling through proof-of-concept after proof-of-concept, burning budget on systems that never ship, while competitors who made different decisions early on are already shipping.
The issue is rarely the model. It’s three specific decisions made before any model is selected, and if you get them right, the production question mostly takes care of itself.
Decision 1: Architecture, Why LLM-Only Becomes a Compliance Problem
The most common architectural mistake in enterprise AI isn’t vendor choice. It treats a large language model as a complete system rather than as a component of a larger one.
A pure LLM has no memory beyond its training cutoff, no access to your source-of-truth data, and no built-in way to verify what it just said. For casual consumer use, fine. For a pharma company producing drug interaction summaries, or a healthcare operator pulling patient records, a confidently incorrect answer isn’t a minor inconvenience; it carries real regulatory weight.
The cost of being wrong in those sectors runs into the millions before anyone budgets for remediation, and the legal team’s patience tends to run out before the ML team’s does.
This is the pattern we see most often in our AI development work: teams arrive with a model-first mindset and discover too late that the model was never the risk.
What Grounding Actually Buys You
This is where Retrieval-Augmented Generation (RAG) matters. Instead of relying on what the model memorized months ago, a RAG architecture retrieves relevant context from your own curated knowledge base at the moment a query is made.
The output is traceable to a specific policy document, regulation, or dataset. That traceability is the minimum bar for anything that has to survive an audit, and it’s the single clearest marker separating a deployable system from a demo.
Grounding is the discipline behind this. Without it, you have a fluent text generator with no accountability for what it produces. With it, you have a system whose answers can be checked and, more importantly, whose failures can be diagnosed.
Why Are Architecture Mistakes the Most Expensive To Unwind
Architectural decisions are also the most expensive to undo after the fact. Retrofitting grounding, retrieval, and verification onto a system originally built as LLM plus wrapper generally means rebuilding the pipeline from scratch.
We’ve written about this pattern before: in Why AI Makes Your Platform More Expensive to Maintain, Not Less. Shortcuts at the architecture layer compound into maintenance debt faster than almost anywhere else in the stack.
The teams we see save time on the POC by skipping grounding almost always end up spending two to three times that saving reworking the system once real data starts flowing through it. The math isn’t close.
Which leads to the next question: even the best architecture falls apart if the data feeding it isn’t looked after.

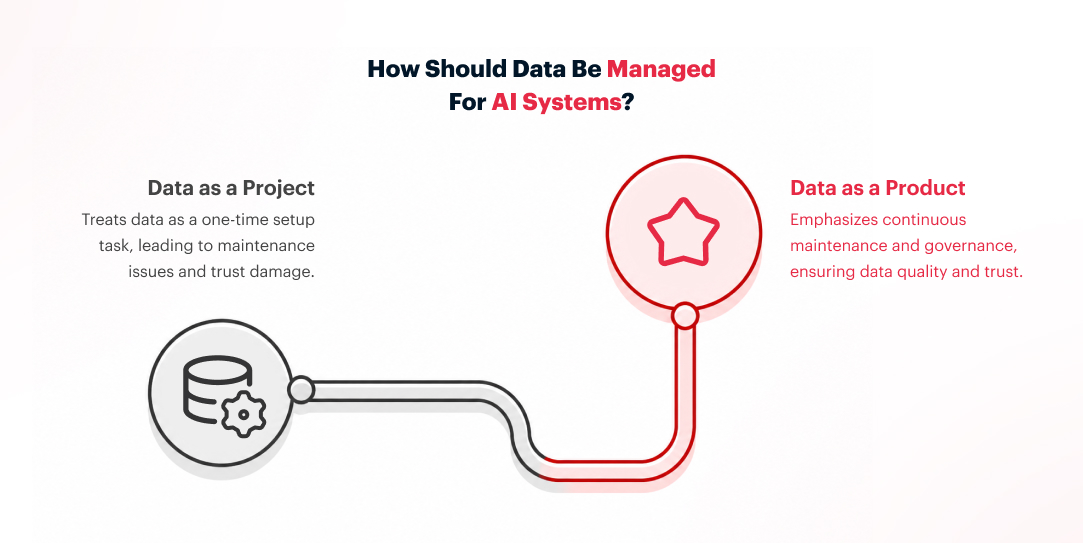
Decision 2: Data as a Product, Not a Project
Once architecture is settled, most teams hit the second failure point, and it hides well. Data gets treated as a setup task. Someone cleans a dataset, labels it, hands it over, and the pilot moves on.
Then the underlying data shifts, new products, renamed fields, changed policies, a vendor integration that breaks and gets patched without anyone updating the pipeline, and the model starts producing subtly wrong answers. Nobody owns the problem, because nobody owns the data.
Project versus Product: The Difference That Matters
Data treated as a project is done once. Data treated as a product is maintained continuously. The difference comes down to governance: a named owner accountable for quality, a versioning scheme that makes changes traceable, defined consumers, and clear agreements about what the data is supposed to deliver.
The same discipline you’d apply to any internal software service, because AI systems are internal software services, whether they get labeled that way or not.
Without this structure, AI systems degrade quietly. The model doesn’t throw an error. It just produces outputs that are a little bit off, and by the time the pattern is visible in user complaints, the trust damage has already been done. And trust is hard to recover in AI. Once a user has watched the system confidently invent something, they start second-guessing the answers that were actually right.
The Engineering Link Most Teams Miss
The framing of data as a product isn’t new; it comes from the data mesh work published on Martin Fowler’s site by Zhamak Dehghani, which argued that treating data as owned, versioned, contract-driven infrastructure was the only way to scale it across an organization. AI systems have made that argument non-optional. Without it, governance doesn’t scale on its own, and the whole thing eventually sags under its own weight.
The organizations we consistently see move from POC to production share one trait. Data products are foundational infrastructure to them, not departmental afterthoughts. Every dataset feeding the AI system has an owner, a version history, and a quality contract. That doesn’t sound exciting, and it isn’t, but it’s what separates teams that ship from teams that cycle.
Decision 3: The Reliability Gap
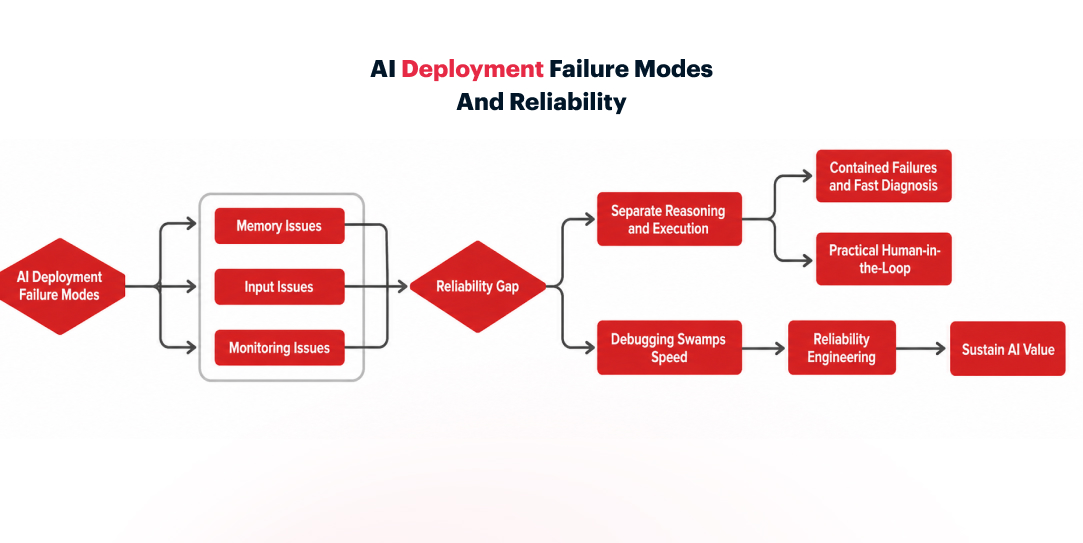
Even with sound architecture and well-governed data, a third failure mode quietly dismantles AI deployments: reliability. This one has nothing to do with the model and everything to do with what surrounds it. And in our experience, this is where the gap between a good pilot and a shipped system usually shows up.
Memory is Usually What Breaks First
Agents built for a pilot typically have no persistent state. Every interaction begins from zero. That’s invisible in a demo, where the conversation is short and scripted.
In production, users reference something they said last Tuesday, switch topics mid-session, abandon a flow, and resume it three days later. Without persistent memory and state management, the agent appears broken to users who’ve done nothing wrong. State isn’t an enhancement or a nice-to-have. It’s a precondition for anything multi-turn.
Inputs Are Usually What Breaks Next
Production users don’t submit clean queries. They paste broken PDFs. They use internal shorthand that the training data never saw. They copy formatting from emails. The underlying business data drifts as market conditions shift.
Edge cases that were quietly scoped out of the pilot become the modal case in production, and systems that weren’t instrumented to catch them fail silently, with the first signal of trouble arriving as a customer escalation, usually on a Friday afternoon.
Monitoring is Usually What Breaks Last, And Most Expensively
Teams that bolt observability on after launch always find problems late. Teams that instrument reliability metrics from day one catch the same issues weeks before users notice.
The difference isn’t tooling; decent observability is commoditized now. It’s sequencing. Monitoring belongs in the deployment plan, not in a Q4 ticket that keeps getting deprioritized.
Separating Reasoning From Execution
One architectural pattern consistently helps here: keep the reasoning layer (what the agent decides) separate from the execution layer (what it actually does). When reasoning goes wrong, you don’t want it to corrupt your data pipeline. When an execution step times out, you don’t want it to cascade back into the model’s context and confuse the next decision.
Keeping these concerns isolated makes failures contained and diagnosis fast, and it’s what makes human-in-the-loop intervention practical, which matters enormously in any regulated workflow.
This is the same discipline we wrote about in Why Your AI Tools Are Making Your Release Cycle Slower. Teams that skip the reliability layer don’t ship faster with AI. They ship less reliably, and the debugging time swamps whatever speed they thought they’d gained.
Reliability engineering is genuinely unglamorous work. Nobody demos a monitoring dashboard. But it’s the thing separating teams who sustain AI value from teams still debugging the same agent six months later, and the compounding effect over a year of production is enormous.
The Path from POC to Production ROI
The pattern across failed enterprise AI is consistent. Resources go into pilots. The demo impresses. Adoption stuck when real complexity arrives. MIT’s findings aren’t a matter of bad luck or poor execution; they point to a structural issue with how organizations sequence foundational decisions.
The fastest diagnostic we’ve found is an audit. Look honestly at the current pilot and list every assumption it depends on: clean inputs, short sessions, supervised calls, pre-tuned prompts, and excluded edge cases.
Then ask which of those assumptions will still hold when real users arrive. The gap between those two lists is the distance you still have to close, and whether the pilot ships usually come down to whether that distance is being actively worked on or quietly deferred until someone notices the launch date slipping.
From there, the priority shift is pretty simple.
- Deprioritize model selection: The three decisions above, architecture, data as a product, and reliability engineering, determine outcomes far more than which model sits at the center. This is the least intuitive lesson and the most important one.
- Build cross-functional ownership: AI delivery that stays inside engineering tends to stall. Product managers, data engineers, and domain experts working together is what closes the gap between “the model works,” and users are actually served.
- Treat repeatability as the success metric, not demo quality: An agent that works 100 times in a row on real inputs is a better outcome than one that works once, spectacularly, on rehearsed prompts. The boring system wins here.
Bottom Line
The 5% of teams that consistently reach production don’t have better models. They have better discipline when it comes to the decisions most teams skip. That discipline is learnable, and it’s available to any organization willing to prioritize infrastructure over spectacle.
Examples of what this looks like in practice, across edtech, healthcare, and enterprise SaaS, are in our client case studies.
If you’d like to walk through where your own pilot sits on this curve, get in touch with our team, and we can run the demo-conditions audit together in about 45 minutes.
FAQs
Frequently Asked Questions
Why do most enterprise AI pilots fail to reach production?
Most pilots fail because they were built for conditions that don’t exist in production. Clean data, supervised calls, short interactions, and rehearsed prompts make the model look capable in a demo, but none of that is true once real users arrive. The three most common structural reasons are poor architecture (treating an LLM as a complete system rather than a component), weak data ownership (no named owner, no versioning), and missing reliability infrastructure (no persistent memory, no monitoring, no edge-case handling). Model quality is rarely the actual issue.
What is Retrieval-Augmented Generation (RAG) and why does it matter for enterprise AI?
RAG is an architecture that has the model retrieve relevant context from your curated knowledge base at query time, rather than relying entirely on what it memorized during training. This matters because enterprise AI must be auditable; outputs must be traceable back to specific source documents, current policies, or verified data. In regulated sectors like pharma, fintech, and healthcare, a confidently wrong answer from an ungrounded LLM isn’t a bug; it’s a compliance event. RAG is the minimum bar for anything that needs to survive legal review.
What does it mean to treat data as a product rather than a project?
Treating data as a product means applying the same discipline you’d apply to any internal software service: a named owner accountable for quality, version histories, defined consumers, and clear contracts about what the data is supposed to deliver. A data project gets cleaned once and handed over. A data product gets maintained continuously. The distinction matters because AI systems degrade silently when their underlying data drifts; the model doesn’t throw errors, it just starts producing answers that are quietly wrong, and by the time users notice, the trust damage is already done.
What's the single most useful first step to move an AI pilot toward production?
Run a “demo conditions” audit before anything else. List every assumption the current pilot depends on: clean inputs, short sessions, supervised calls, rehearsed prompts, and excluded edge cases; and ask which of those will still be true when real users show up. The gap between those two lists is usually the real project, and it’s almost always bigger than the team expects. Whether the pilot ships often come down to whether that gap is being actively closed or quietly deferred.
Author
