Why AI Makes Your Platform More Expensive to Maintain, Not Less

The conversation happening in the market right now about AI adoption begins with the same promise: efficiency. Lower operational costs. Automation that replaces expensive manual processes. A platform that gets smarter over time and pays for itself. The pitch seems interesting, and in some well-scoped cases, it’s even true, at first.
But there’s a structural reality most AI vendors, system integrators, and internal champions do not surface in the early conversations: AI platforms are categorically more expensive to maintain than the traditional software they replace. Not marginally more expensive. Structurally, compoundingly, increasingly more expensive, through a combination of forces that conventional IT budgets were never designed to handle.
This isn’t an argument against AI adoption. We help enterprises design and integrate AI systems every day at LN Webworks. It is, however, an argument against going into a blind spot.
The organizations that successfully sustain AI investments are the ones that understood the full cost picture before they committed, not those who discovered it mid-deployment, when the budget is already spoken for.
This piece is the cost picture. No vendor positioning. No optimistic projections. Just the mechanics of why AI maintenance costs compound, what the numbers actually look like, and what your team needs to plan for.
1. The Baseline Problem: AI Is Not Traditional Software
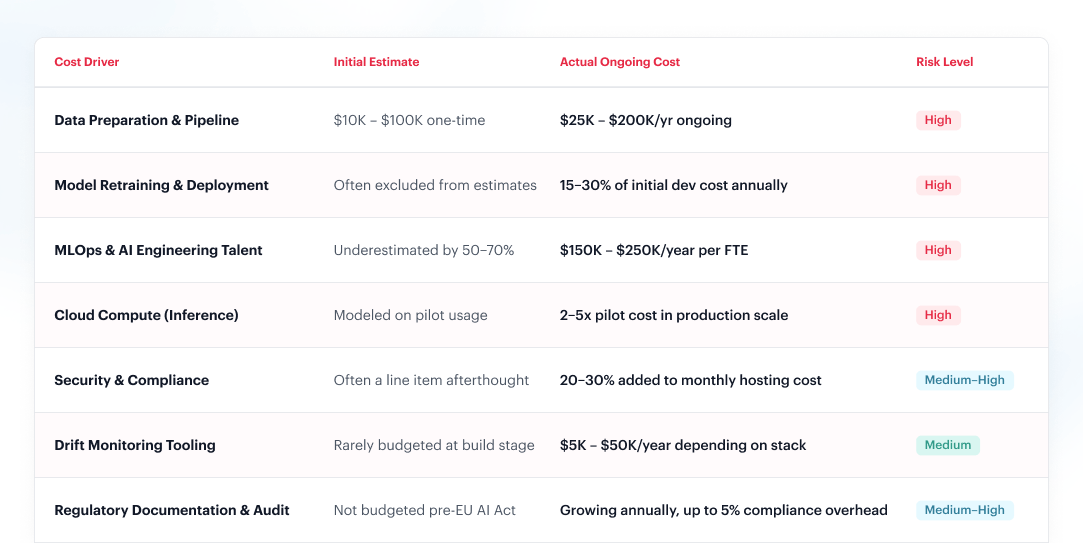
To understand why AI maintenance is categorically different, you have to understand what you’re actually maintaining. Traditional software, a CRM, an e-commerce platform, and a reporting dashboard follow a predictable decay curve.
It works as built, degrades slowly as dependencies update, and requires periodic patching and version upgrades. The maintenance burden is real but bounded.
AI systems follow a different physics entirely. A trained machine learning model is an overview of the world at the moment it was trained. The moment it goes into production, the world starts diverging from that snapshot.
Consumer behavior shifts. Market conditions change. Fraudsters adapt. Languages evolve. Regulatory environments tighten. And the model, frozen in its training data, starts making increasingly stale decisions, often invisibly, without obvious error messages or system failures.
This degradation is called model drift. It is the decline in a machine learning model’s predictive accuracy over time caused by changes in real-world data distributions (data drift) or underlying relationships (concept drift). It is the central driver of AI maintenance costs that no vendor slide deck shows you. It’s not a bug. It’s not a failure of implementation. It’s simply what AI systems do when deployed in a world that keeps moving.
2. Model Drift: The Silent Tax on Every AI System in Production
Model drift is not theoretical.
The COVID-19 pandemic provided the most vivid real-world demonstration in recent history: machine learning models trained on pre-pandemic spending, travel, and behavior patterns became unreliable almost overnight as the world shifted dramatically.
Fraud detection systems built on historical transaction data became less effective as fraudsters adapted their methods. Recommendation engines surfaced irrelevant content as usage patterns changed. Every affected organization faced the same emergency: retrain or accept degraded performance.
But pandemic-scale shocks are the dramatic version of a constant, quieter process. Fraud systems drift as fraudsters evolve. Demand forecasting models drift as supply chains shift. Customer scoring models drift as customer behavior changes.
In every case, the cost of correction, new training data acquisition, compute resources for retraining, engineering time for validation and re-deployment, falls entirely on the platform owner.

The cost mechanics of retraining are often misunderstood at the planning stage. Retraining is not just a compute expense; it requires data freshness (data pipelines must continuously ingest new labeled data), human validation (model outputs must be verified before promotion), A/B testing infrastructure (new model versions must be compared against production baselines), and rollback capability (if a new version underperforms, the previous state must be restorable). None of this was part of the original build budget. All of it is ongoing operational overhead.
For high-stakes applications, fraud detection, healthcare, and financial risk, retraining cycles may be required monthly or even weekly.
For lower-stakes systems, quarterly retraining is common. In every case, the resource requirement is recurring, not one-time.
3. Compute Inflation: The Bill That Grows Even When Nothing Changes
Even a perfectly stable, well-maintained AI model costs more to run every year, because the underlying computing infrastructure it depends on is getting more expensive at a rate that has no precedent in conventional IT.
According to IBM’s Institute for Business Value, the average cost of computing was expected to climb 89% between 2023 and 2025, with 70% of surveyed executives citing generative AI as the primary driver.
This isn’t a market correction. It’s a structural repricing driven by the physics of what AI requires: GPU-heavy infrastructure in short supply amid surging global demand, running workloads that consume orders of magnitude more energy than conventional software.
The energy consumption is particularly unforgiving for AI-heavy platforms. MIT Technology Review analysis found that training GPT-4 alone consumed over 50 gigawatt-hours of energy, enough to power San Francisco for three days, at a cost exceeding $100 million.
Training frontier-scale models is a specialized problem, but inference, running the model for every user query, every API call, every automation trigger, is where the cost becomes an operational reality for every enterprise deploying AI in production. And inference costs don’t scale linearly; they scale with usage, often unpredictably.
Goldman Sachs projects a 160% increase in data center power demand by 2030. Meanwhile, AI-specific servers consumed an estimated 53–76 TWh in 2024 and are projected to reach 165–326 TWh annually by 2028.
For platform teams, this means the unit economics of AI inference will likely continue worsening unless workloads are actively optimized, not just deployed and forgotten.
4. The Talent Premium: Building Your Team Is Just as Expensive as Building the System
AI systems cannot maintain themselves. They require a specialized class of engineering talent, MLOps engineers, ML platform engineers, data engineers, and AI governance specialists, whose compensation benchmarks operate in a category entirely separate from traditional software engineering.
The numbers are stark. According to an analysis of 10,133 AI/ML engineering job postings in the U.S. between November 2024 and January 2025, the median AI/ML engineering salary is $187,500, with the middle 80% of roles paying between $122,000 and $265,000 annually. Senior roles cluster around $240,000, placing them in the top 4% of all U.S. earners.
The talent market dynamic compounds the cost further. LinkedIn Talent Insights identifies MLOps as one of the fastest-growing roles in tech, with 9.8× growth over five years.
Compensation for ML and MLOps roles has risen ~20% year-over-year, with multiple competitive offers now standard for experienced candidates, sometimes with 48-hour decision windows.
For companies outside traditional tech hubs or with lower brand recognition, competing for this talent means paying above-market rates or accepting lower-quality candidates.
Critically, this isn’t just a one-time hiring challenge. AI maintenance requires continuous human expertise across several distinct functions: data pipeline management, model monitoring, drift detection, retraining orchestration, compliance documentation, and output quality assurance.
Each function requires skilled practitioners. Each practitioner commands a premium. And unlike traditional engineering roles where experienced staff can often maintain systems with relatively stable effort, AI systems demand increasing expertise as they grow more complex and as the data they depend on grows more voluminous.

5. Regulatory Overhead: The Compliance Cost That Doesn’t Appear in the Build Phase
Most engineering teams encounter it for the first time mid-deployment, after the architecture decisions have already been locked in.
The EU AI Act, the world’s first comprehensive AI regulation, has been in effect since August 2024 and is being implemented in phases. It applies to any organization that deploys an AI system affecting EU users, regardless of where the company is headquartered. That last part catches a lot of teams off guard: you don’t need an office in Berlin to be in scope. If your platform reaches EU customers, you’re subject to it.
What the Rules Actually Require?
The Act works on a risk tier. Most enterprise AI sits in the middle tier; not prohibited, but regulated:
Tier 1: Minimal Risk (no ongoing obligations)
AI spam filters, content recommendation engines, and product search ranking. These fall outside active compliance requirements. You can deploy and maintain them without regulatory overhead.
Tier 2: Limited Risk (transparency obligations only)
Chatbots and AI-generated content tools. You must disclose to users that they’re interacting with AI. This is a low-cost, one-time implementation, but it must be maintained and kept accurate as your system evolves.
Tier 3: High Risk (full ongoing compliance obligations)
AI is used in hiring and CV screening, credit scoring, insurance underwriting, healthcare diagnostics, educational assessment, and law enforcement. These require continuous risk management documentation, audit trails, human oversight mechanisms, and regular conformity reviews.
Prohibited: Banned outright (no compliance path)
Social scoring systems, real-time public biometric surveillance, AI that exploits psychological vulnerabilities, and manipulative subliminal techniques. Using these exposes you to fines up to €35 million or 7% of global turnover, regardless of intent.
The Cautionary Tale: What Happened to xAI, and What It Means for You
The clearest real-world signal of where AI regulation is heading arrived in February 2026, when French prosecutors raided X’s Paris offices as part of a criminal investigation into Grok’s deepfake capabilities.
Elon Musk and the company’s former CEO were summoned for questioning. The charges included seven criminal offenses, among them distributing content that violated EU fundamental rights protections and operating a platform without adequate safety controls.
Note carefully what xAI’s compliance strategy had been: geoblocking, restricting certain Grok capabilities in specific jurisdictions while leaving them active elsewhere.
Regulators did not accept this as compliance. French prosecutors treated the geoblocking itself as evidence of knowledge: xAI had acknowledged the harm potential of those features, yet the content still reached French users through VPNs and unprotected surfaces.
This is not an isolated edge case involving a uniquely reckless company. It is the first clear data point on how the EU AI Act’s enforcement architecture works in practice, and the lesson for every enterprise AI team is direct: the compliance window is your build window, not your enforcement window. By the time formal investigation begins, your historical deployment practices have already created liability. Regulators investigate backward.
6. Data Infrastructure: The Cost Nobody Plans for Because Nobody Sees It Coming
AI models don’t just consume compute cycles; they consume data. Continuously. And the quality, freshness, and governance of that data is not a one-time setup problem. It is a permanent operational discipline with its own engineering, storage, and human oversight costs.
Industry research consistently finds that data preparation consumes 50–70% of total AI project time and budget. This is true at the initial build phase. What is less discussed is that it remains true, at scale, throughout the operational life of the system.
Approximately 96% of businesses begin AI projects without sufficient high-quality training data, requiring unplanned investments of $10,000–$90,000 at the outset.
But data quality is not a problem you solve once. It is a problem you manage continuously, because production data drifts, customer inputs evolve, and edge cases accumulate.
The data infrastructure challenge also creates a specific form of AI technical debt that is uniquely hard to untangle: data entanglement.
When an AI model is trained on a dataset, it becomes coupled to the statistical patterns in that dataset in ways that are not always transparent or modular.
Changing one data source, even for good reasons, can destabilize model behavior across unrelated functions. This means that data infrastructure decisions made at build time create long-term maintenance constraints that weren’t visible at the time of the original architectural choice.
There is also a cost that rarely appears in migration plans: revalidation.
Moving a model to a new platform or inference engine does not guarantee it will produce the same outputs. Subtle differences in how inference engines handle tokenization, temperature, sampling, and floating-point precision can shift model behavior in ways that are real but not immediately obvious.
Expected results that were calibrated on one platform need to be re-established on the new one, through regression testing, output comparison, A/B benchmarking, and in some cases, additional fine-tuning passes.
This validation work requires engineering time, labeled evaluation datasets, and, in regulated contexts (financial services, healthcare, HR), formal sign-off processes.
For large production systems, revalidation alone can consume 6–12 engineering weeks and a substantial share of the migration budget, a cost that often doesn’t appear in migration proposals until the work is already underway.
7. Vendor Lock-In and Platform Migration: The Cost You Pay When You Want to Leave
Many AI platform deployments begin with a cloud-hosted, API-driven model, OpenAI, Google Vertex AI, AWS Bedrock, Azure AI, because the startup cost is low and time-to-demo is fast.
This is often the right initial choice. However, it becomes a significant maintenance liability when the organization needs to migrate, renegotiate, or restructure its AI architecture.
Platform migration expenses for AI systems typically exceed the original implementation cost by 3–5×. This multiplier reflects a set of costs that don’t exist in traditional software migrations: retraining fine-tuned models on a new platform, re-engineering data pipelines for different API structures, revalidating model outputs against a new inference engine, and rebuilding monitoring and alerting tied to the previous vendor’s tooling.
Every customization made for a specific vendor, and most production AI systems accumulate significant customization, creates switching costs that accrue silently while the original contract is in place.
A Concrete Example: Moving from Cloud to Private Infrastructure
The most common migration pattern in 2026 is this: an organization that started on a public cloud AI platform, attracted by fast setup and no upfront hardware cost, discovers that at production scale, cloud inference costs are consuming a disproportionate share of the AI budget, and begins evaluating a move to private or hybrid infrastructure. The economics of this shift are well-documented.
GEICO’s decade-long cloud migration resulted in costs doubling and reliability declining, ultimately prompting a move back to hybrid. Dropbox moved petabytes of data off AWS to owned infrastructure and generated $74.6 million in cumulative savings.
An IDC survey found 86%of CIOs plan repatriation of CIOs planned to repatriate some workloads in 2025, the highest rate ever recorded. Most aren’t executing full cloud exits; they’re selectively moving high-volume, steady-state AI inference workloads that are cheapest to run on owned hardware and most expensive at cloud metered rates.
8. What Good AI Architecture Actually Costs, and What It Buys You
None of this is an argument for avoiding AI. It is an argument for accurate planning. The organizations that achieve durable AI ROI share a set of architectural and operational choices that front-load cost clarity, and in doing so, dramatically reduce the likelihood of compounding surprises.
Plan for Technical Debt as a First-Class Budget Item
IBM’s research makes the case numerically: treating debt remediation as a direct ROI enabler, not an IT chore, is the single most powerful predictor of AI investment success.
This means including debt repayment in the AI business case from day one, allocating dedicated engineering time for maintenance in every sprint, and measuring debt density regularly rather than waiting for system failures to surface.
Build Modular, Not Monolithic
AI technical debt is substantially harder to repay in monolithic architectures where data pipelines, feature engineering, and model logic are tightly coupled.
Modular architectures with versioned data pipelines, replaceable model components, and clear handoff boundaries between data engineering and ML engineering allow individual components to be updated, retrained, or replaced without destabilizing the whole system.
Size the Model to the Task
One of the most consistent cost optimization findings across MLOps teams: organizations routinely over-engineer AI solutions, deploying expensive frontier models for tasks that smaller, domain-tuned models would handle at a fraction of the inference cost.
Using the right model for the task can reduce costs by 10×model right-sizing, not through compromise on quality, but through appropriate scoping. The same logic applies to retraining: share base models and reusable components across teams rather than retraining from scratch for each use case.
Instrument Everything from the Start
Drift monitoring, cost attribution, and usage tracking are not features to add later. They are the foundation of AI operational visibility. Organizations with real-time cost dashboards and automated drift alerts at defined thresholds reduce unexpected AI cost overruns by 35–45% fewer overruns. This is infrastructure that should be specified as a requirement in the build phase, not retrofitted after a cost shock forces the conversation.
Account for Compliance Before You Deploy
The EU AI Act creates obligations that take time to implement: risk management systems, documentation frameworks, and human oversight mechanisms.
Organizations that begin compliance preparation at the system design stage have substantially lower remediation costs than those that address compliance as an afterthought post-deployment.
The same principle applies to sector-specific regulations in finance, healthcare, and employment contexts. Regulatory architecture is platform architecture. It cannot be decoupled.

Closing Thoughts: Budget for What You’re Actually Building
The AI platforms generating durable competitive advantage in 2026 are not the ones with the most sophisticated models or the most ambitious initial deployments.
They are the ones whose teams understood before the first dollar was spent that AI is infrastructure, not a project. Infrastructure that requires ongoing investment, continuous expertise, compounding operational discipline, and honest accounting of what it costs to maintain.
The organizations that treat AI as a one-time capital expenditure discover the reality through budget shocks, degraded performance, compliance exposure, and technical debt that blocks every subsequent initiative.
The organizations that plan for it correctly, building modular architectures, investing in MLOps talent, instrumenting drift early, and accounting for regulatory obligations, find that the maintenance burden, while real, is manageable and predictable.
The difference between these outcomes is not technical sophistication. It is planned honesty. And that conversation is best had before the contract is signed, not after the first retraining invoice arrives.
If you’re evaluating an AI platform investment or auditing the true cost of one already in production, our team at LN Webworks can help you get the full picture. We build AI systems and digital platforms designed for long-term operational sustainability, not just impressive pilots. It’s a conversation worth having early.
Author
