Why 88% of AI Projects Fail Before Production: The Operational Gaps Most Teams Miss

For every 33 AI initiatives that get approved, funded, and staffed, four reach a live production environment. That figure comes from IDC and Lenovo research, and it holds across industries, company sizes, and use cases.
The overwhelming majority of AI projects stall somewhere between a promising demo and a working system.
88% of AI projects do not fail because the models are weak. They fail because production systems are messy, operational workflows are fragmented, and organizations underestimate the engineering discipline required to move from pilot to deployment.
The failure is rarely in the technology itself. It’s in three conditions that consistently sit between a controlled pilot and a production-ready deployment: a gap between test environments and real operational complexity, data that isn’t ready for live systems even when it appears clean, and leadership teams that approve projects before anyone has agreed on what deployment success actually looks like.
Each of these problems is solvable. But they require being addressed in the right order, and before development begins, rather than after.
This piece covers all three, and the operational pattern that separates organizations that push through them from the ones that stay stuck.
The Gap Between Testing and Production
A controlled pilot has everything production doesn’t: curated data, linear workflows, and a team available to manage anything unexpected. Production has the opposite.
Workflows branch in ways no test scenario anticipated. Connected systems return incomplete data on schedules nobody designed for. Users behave in ways that look nothing like QA conditions.
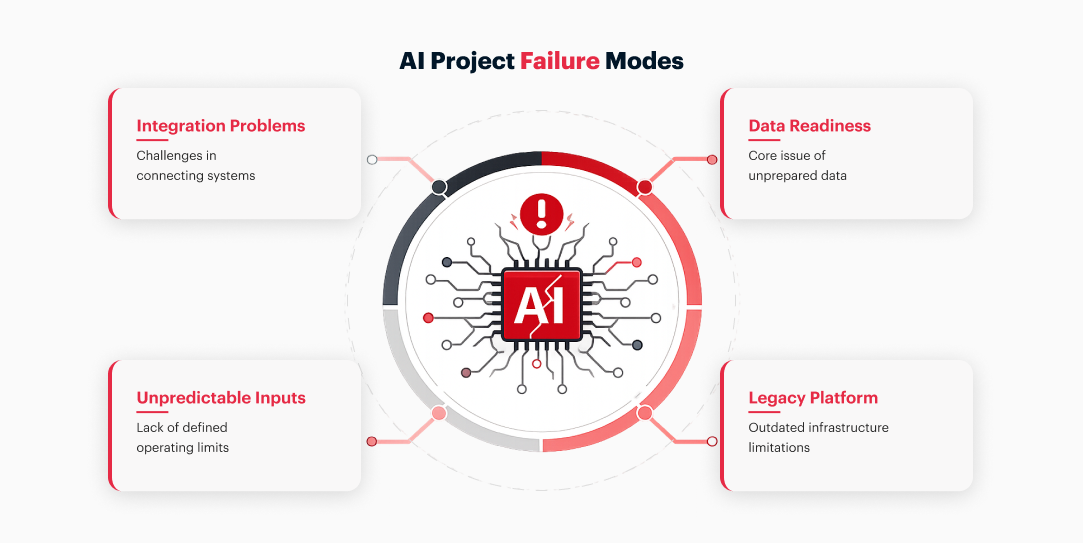
Two failure modes appear frequently enough to name.
The first is the legacy platform problem.
Most enterprise technology stacks weren’t built for the data volumes and request frequencies that AI-powered systems generate. Fragmented databases, outdated connection interfaces, and inconsistent data formats create friction at every integration point. A model that performs well against a curated dataset often degrades significantly when connected to live infrastructure that was built for different demands.
The second problem appears when AI systems operate outside clearly defined constraints.
AI systems capable of taking independent action require predictable inputs and clearly defined operating limits. When those conditions don’t exist, the system encounters situations outside its design parameters and either stalls, generates unreliable outputs, or requires constant human intervention to remain trustworthy. In practice, operational complexity often increases.
Both failures are integration problems before they are technology problems. And beneath both of them, in almost every case, is the same upstream issue: the data was never ready.
Why Production-Ready Data Is Not the Same as Clean Data
The gap between pilot and production is most visible at the integration layer. But the underlying cause, in most cases, is that the data itself was never ready for live deployment.
Fragmented systems, inconsistent record formats, and information siloed across disconnected platforms create conditions where a well-designed model starts producing unreliable outputs the moment it connects to real operational data.
The problem doesn’t surface during the demo. It surfaces after deployment, when accuracy drops, and stakeholder confidence erodes quickly.
Three warning signs appear consistently in projects that stall at this point.
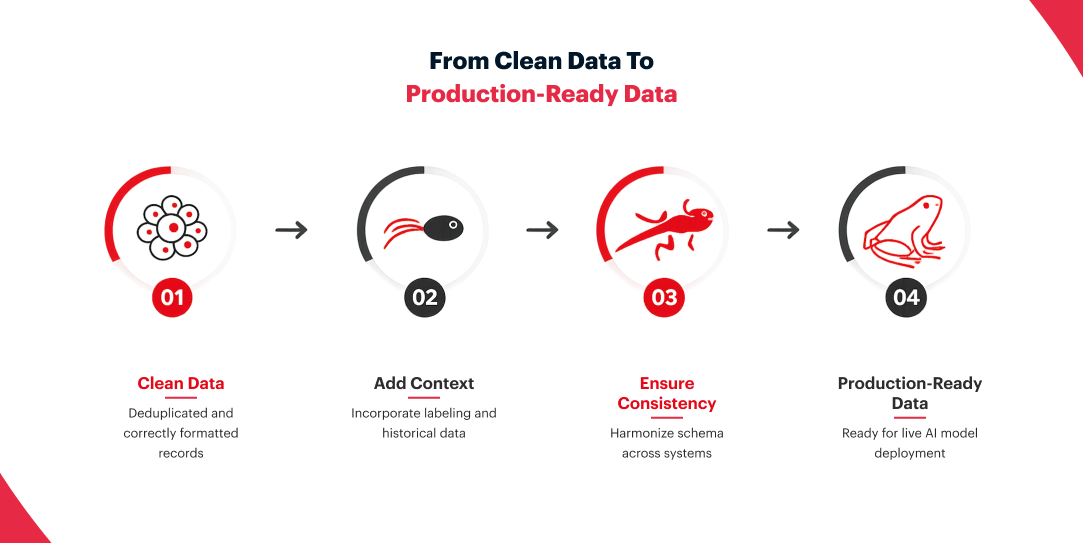
First: formatted data is not the same as production-ready data. Records can be deduplicated and correctly formatted, but still lack the labeling, historical context, and consistency that live systems require. Clean on the surface doesn’t mean ready for deployment.
Second: schema mismatches across fragmented systems cause models to draw connections between data points that don’t actually exist, generating outputs that are confidently incorrect. This kind of error compounds quickly once a system is live.
Third: finding data fragmentation late in the development cycle is expensive. Reworking integration foundations after a model has already been trained against flawed inputs can reset a project timeline by months, and it often means rebuilding stakeholder trust from the beginning.
Organizations that address these conditions before development begins avoid the most common and most costly reasons for abandonment. The ongoing cost of weak data infrastructure extends well past the build phase, which we’ve covered in depth in our piece on why AI makes your platform more expensive to maintain. The problems start earlier than most teams budget for.
What the 12% Do Differently
The barrier isn’t a better algorithm or a larger budget. It’s a different approach to the work that happens before any model gets built.
Research from MIT Sloan and multiple enterprise surveys consistently separates organizations with durable AI deployments from those cycling through expensive experiments at the same point: the former treat AI as a business process change, not a standalone technology update.
They don’t add AI to existing workflows and hope for different results. They redesign the workflows first. The operational differences are concrete and consistent.
The contrast table below maps them against the patterns seen in the 88%.
| WHAT MOST ORGANIZATIONS DO | WHAT THE 12% DO |
|---|---|
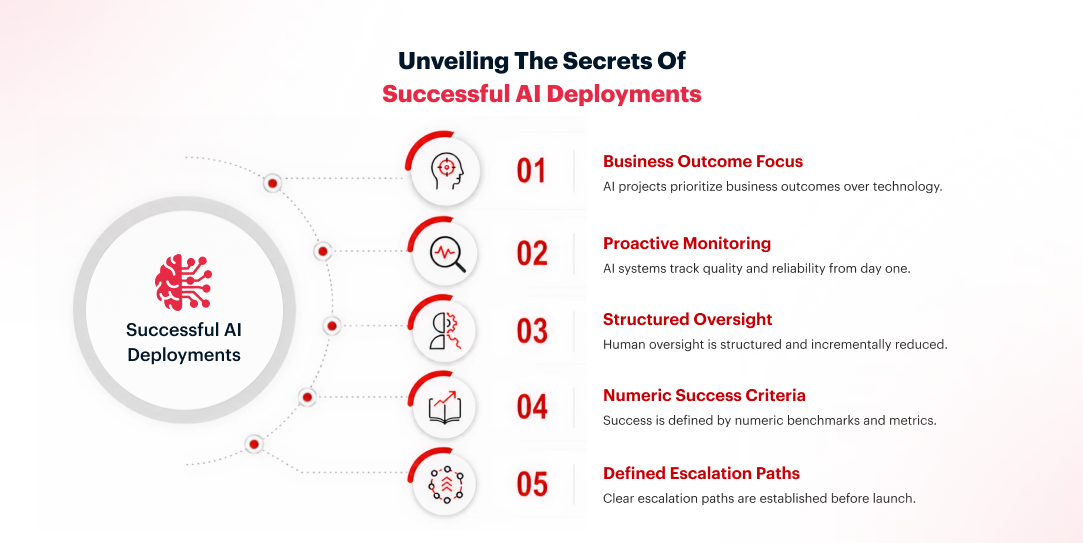
| Technology is selected first, then requirements are defined around it | Business outcome is defined first; technology follows from that definition |
| Performance monitoring is treated as a post-launch configuration task | Output quality and reliability tracking are built into the system architecture from day one |
| Human oversight is removed once the system is live | Structured review runs through the first months of production, reduced incrementally as performance metrics stabilize |
| Success is defined as “the demo worked.” | Success criteria are numeric, set before development starts, and separated into month-one and month-six benchmarks |
| Escalation paths for unexpected outputs are figured out reactively | Clear escalation paths and review triggers are defined before the system goes live |
The performance monitoring point deserves more attention than it usually gets.
Organizations that reach production don’t treat monitoring as something to configure after launch. They track output quality and reliability from the first production release, and they schedule review cycles tied to performance data rather than calendar dates.
This is the mechanism that surfaces the edge cases controlled pilots never catch, and it’s what allows teams to reduce human oversight responsibly rather than arbitrarily.
Projects frequently encounter failures when human oversight is removed too early. The teams that avoid it treat the early review period as a source of signal about where the system needs improvement, not as evidence that it isn’t ready. That distinction matters more than it sounds.
Agreeing on What Success Looks Like Before You Build
The operational gaps above are real and fixable. But there is a business-level problem that typically precedes all of them: organizations approve AI projects without deciding what deployment success actually means. Technical teams build toward a working demo.
Leadership assumes they’re building toward a production system. That gap doesn’t surface until month three or four, when the question shifts from “does it work?” to “what does this cost at scale, and is this what we needed?”
The organizations that avoid this pattern define measurable outcomes before development starts, and they do it separately for month one and month six. Early proof metrics and sustained production performance are not the same benchmark. Treating them as equivalent leads to scope expansion, expectation drift, and initiatives that lose internal support before reaching deployment.
This pattern is so common that it has a name: it’s the stage where otherwise viable projects get quietly defunded, not because they failed technically, but because nobody agreed upfront what “working” meant at scale.
Defining ROI criteria before the first line of code is written is not a planning formality. It’s the decision point that determines whether a project has a realistic path to deployment or a well-funded prototype that expires without ever being fully realized.
The AI technical debt patterns we see in production almost always trace back to this alignment gap. Teams built toward capability. They didn’t build toward an outcome. The debt accumulates in the space between those two goals.
The Path Forward
The 88% figure is not a technology problem. It is a systems problem. Data foundations are weak before deployment begins. The gap between controlled test conditions and production complexity is consistently underestimated.
Clarity about what success looks like is absent before the first model runs. These are not random failures. They are predictable failures with predictable solutions.
Organizations that reach production and stay there don’t have better models than the ones that stall. They build better systems. They address integration gaps before scaling, not during.
They define what ROI means before writing a single line of code. They treat AI deployment as a production engineering discipline, not a research exercise. And they maintain oversight long enough to actually learn from the system before reducing it.
That discipline is the actual competitive advantage in this space. While organizations cycle through the proof-of-concept stage without a realistic path forward, teams with solid foundations move deliberately toward production. If you want to see how that works in practice rather than in theory, our client case studies give a clearer picture than any framework document.
Stop building models. Start building systems.
If any part of this raises questions about where your current initiative actually stands, that conversation is worth 30 minutes.
FAQs
Frequently Asked Questions
Why do most AI projects fail to reach production?
Three things consistently get in the way: the gap between a controlled test environment and real operational complexity, data that isn’t actually ready for production, and teams that greenlight a project before agreeing on what a successful deployment looks like. None of these are technology problem. They’re process problems.
What is the pilot-to-production gap in AI development?
It’s the difference between testing under controlled conditions and running in a live environment. In a pilot, data is clean, workflows are predictable, and someone is watching closely. In production, none of that is guaranteed, and models that performed well in demos often degrade quickly once connected to real systems and real users.
How important is data quality for AI production deployment?
It’s usually the deciding factor. The problem isn’t dirty data, it’s data that looks clean but lacks the labeling, consistent schemas, and traceable history that production systems actually need. Most teams discover this after deployment, which is the worst time to find it.
What do successful AI deployments have in common?
They start with a business outcome, not a technology choice. Organizations that consistently reach production define what they’re trying to change before selecting tools, build monitoring in from day one, and keep humans in the loop through the early months rather than removing oversight at launch.
Author
